
News about disk hotswap in Linux 2.6 Kernel
News about Dirvish
Summary
Disk to disk backups are fast, cheap, and good; best of all,
you can boot from the backup disk and restore to a virgin drive rapidly.
Swappable IDE-USB2 drive cages from
ViPower are $50,
direct IDE cages (if your kernel is new enough) are $24,
spare trays are $9.
>200GB ATA6 hard drives are pushing 60cents/GB after
rebate (Prices Nov. 2003).
Drive to drive backups are very fast; about 300MB/minute over
100BT ethernet, about 500MB/minute inside the box.
Items required:
Linux machine (Redhat 9 is usable) with two half-height
5.25 inch drive bays available.
IDE Main Hard Drive
IDE Backup Drive (more than one recommended)
ViPower IDE UDMA 133 Super Rack VP-10LSFU-133
ViPower IDE to USB 2.0 SwapRACK VP-1028LSF ...OR...
... a second VP-10LSFU-133
ViPower IDE extra racks VP-15F-100/133
ATA133, LBA-48 IDE drive controller (Promise, Maxtor, other?)
USB2 card or internal connection (NEC chipset, other?)
Hardware Description
The backup server has two drives, housed in ViPower removable cages,
placed in two open 5.25 inch half-height slots on a medium sized
tower case. I also have a full height Exabyte 8205 DAT drive, but
it is no longer used, since the drive-to-drive backups work so well.
With a slot for a CDR, you may be able to get it all done in a three
slot minitower.
I am currently backing up two laptops, the firewall, and the backup
server itself with Dirvish (see below). This is about 80GB of data,
and I rotate 3 drives into the backup slot (a WD 200G , a Maxtor 200G,
and a Maxtor 250G ). Note that a 250G stores a lot more backups than
a 200G, due to the way Dirvish stores incrementals.
One removable cage is the main drive, a 120GB IDE 3.5inch (Maxtor
or Western Digital or Hitachi/IBM Deskstar, I've had no problems
with any of these). This cage is connected to a ATA-6 (LBA-48)
PCI controller card and used to boot the machine. For proper
bare-metal recoveries,
you will need more than the 137GB limit imposed by the older-style
LBA-28 IDE interface that still appears on some motherboards.
Linux versions 2.4.20 (Redhat 9) and higher support the LBA-48
cards I've tried with no problems, including the cards that are
often included with the larger Maxtor drives.
Bartlomiej Zolnierkiewicz, noted kernel coder, writes
"I don't know about any not LBA-48 compliant ATA PCI chipsets.
Some older ones (mainly from ALI) have problems with LBA-48 DMA
but even on them PIO transfers works okay (but they are slow!)."
I haven't verified this information, but I have had problems
with some older PCI IDE cards. Try it out and let me know what works!
The USB2-IDE controller in the ViPower VP-1028LSF Swap RACK cage
supports hot swap. This is the second cage, and holds the IDE backup
drive. The USB dock is a bit slower than a direct ATA133 connection,
but it is faster than the 100 baseT network.
New! The very latest kernels, such as 2.4.22-1.2115.nptl that
ships with Fedora Core 1, contain Alan Cox's IDE hotswap modifications.
This allows a you to swap a drive connected directly to an IDE ATA-133
board. Here's how:
umount /dev/backup
hdparm -b 0 # this disconnects the bus
# power off the cage
# swap the drive
# power on the cage
hdparm -zb 1 # this re-connects the bus
# the z option rereads the partition table
mount /dev/backup /backup
The Linux Kernel must be compiled with USB2, Hotplug, and Large Drive
support; this is the default for RedHat 9 and Fedora. Large drive
support must be compiled in, and not a module, since we will need to
boot from a large drive.
As of mid-March 2004, IDE hotswap has been
removed from the 2.6 series of kernels.
Alan Cox estimates that it may not re-appear until
August 2004. Until then, use a 2.4.22+ kernel, or else use a ViPower
USB2 swap cage.
This setup backs up not only my backup server, but my firewall and
two laptops over 100baseT ethernet. The dirvish initial backup is
a little slow, but once that is done I can generally accomplish
level-0-equivalent evening backups of 80GB of data in under an hour.
Operation - how backup disks are prepared and used
Nothing special is done to the main drive, besides using fewer partitions
than I used to. Since backups and restores are very fast, smaller partitions
confer no backup/restore advantage, and are slow. I run partitions for
root (/), /boot, /home, and /spare. I do a lot of CAD work that generates
huge intermediate files - these do not need backing up, and sit in /spare.
I also keep copies of the distribution disk ISOs, and other large temporary
files in /spare. This large partition takes up about half the main drive.
I used a similar scheme when I backed up to the Exabyte tape drive.
I have two 200 GB backup drives, and a 250 GB backup drive.
In years to come, I expect these to exceed 1TB.
Each drive is divided into two partitions, a 1GB root (/) partition,
with the rest of the space in a /backup partition.
About 400MB of the root partition contains a copy of a working distro,
including all the disk and ethernet tools.
I also include the compilers and program development tools,
in case I need to repair software.
I also include X and Mozilla, so I can get to the Web;
this is a tough call, because X can complicate booting after a
major hardware change.
The boot partition and compact version of Linux on the backup drive
allows me to boot from it if the main disk is trashed. In that case,
I can simply swap drives. I move the bootable backup drive
into the main slot, and the main drive into the backup slot.
I can reformat the main drive, and completely restore every partition
from the data stored in the backup partition of the backup drive.
This is probably the main point of this webpage. A bootable backup
means I do not need to do a multiple-stage restore.
Rather than load from slow distro CDs, then configure the restore
device, then worry about writing over a live file system,
I can simply copy backup data from the backup drive
to the future main drive. This is much faster and safer.
I keep a copy of the backup/boot partition, compressed, on my main
drive. When I build another backup drive, I simply use dd to
copy the partition. I use the grub boot loader, which means
I do not have to align everything just right like I would with LILO;
grub is smart enough to find the kernel image in the boot partition,
even if the disk size changes.
Thus, the procedure for preparing a backup drive:
Partition the backup disk (usually /dev/sda) with fdisk or sfdisk
Use dd to copy the backup/boot image onto /dev/sda1
Use grubinstall to put the grub boot loader onto /dev/sda
Use mkfs to put a file system on the backup partition /dev/sda2
Set up the directories for dirvish
The disk is now ready for the first backup.
Note, in /dev of both the main and backup boot disks, I have a symbolic
link from /dev/backup to the actual partition used for backups (usually
/dev/sda2). This means that my backup and restore scripts are a bit
more hardware independent.
Dirvish
Since I put up a previous version of this document,
I have been learning a better way to do backups than compressed dumps.
This uses a set of perl scripts called
Dirvish
written by J.W. Schultz . This is a wrapper for rsync, which rapidly
syncronizes files between machines. It has a lot of clever ideas.
J.W. Schultz, author of Dirvish, died in March 2004.
I set up a website,
www.dirvish.org,
which is a copy of the website as of 8 September 2003, along with
a wiki and a copy of the 1.2 version of Dirvish.
Contact keithl@keithl.com
if you have any input on the matter.
Think of what a furball this would be if this was closed
source, and the company producing it stopped supporting it!
Dirvish uses rsync to make images of all the file systems of the
local or remote machine on the backup drive.
But then it does something clever; the next time you use dirvish.
it creates the next images with hard links to the previous images,
thus using actual disk space only for the files that have changed.
Thus, the second and subsequent images only consume space for directories
and the files that change. This takes up very little room. The upshot
is that it is cheap and fast to create complete, daily images going back
a long time. Dirvish also has an expire process that eliminates some
of the old virtual images, but with a relatively small image and a large
backup disk (2x the image or better) it is possible to keep dozens to
hundreds of images available.
Because it uses rsync, which is a lot more file savvy than dump, it
is quite safe to use dirvish on a live file system. You might have to
freeze a multi-file database while it is running to have coherent
file sets, but rsync knows how to wait for individual files to settle
down. If you were in the middle of a multifile update (i.e., apt-get
or rpm) while Dirvish is running, it might not see all the files,
resulting in an incomplete app, but the previous days image and
the following days image will have complete and functional versions
of the app. No more dropping down into single user to run backups!
I have just started learning about Dirvish. The documentation is
difficult to read, the code is virtually uncommented, and the
bank/vault/image metaphor is hard for me to understand. But the
underlying perl code looks well written and capable; I hope to
help improve the documentation myself. I will have a lot more to
say about Dirvish in a few weeks.
Dirvish creates LOTS of directories, which are relatively small,
and make multiple connections to the underlying files. At first,
I understood this to mean that the backup file system should be
built with more inodes than normal, but it appears that the default
percentage chosen by mkfs is about right. I am currently using
66% of the disk space and 28% of the inode space on my backup
drives (11/13/2003); while the remainder of the drive will be
filled with a lot of directories and relatively few files, the
inode space will probably outlast the file space the backup partition.
If your regular filesystem contains a lot of small files and
directories, when you prepare the backup drive you may wish to
consider using more inodes than the default. I have not found
this to be necessary.
Dirvish and /var/log
There is a weakness of the rsync/dirvish approach to backup; files
that change even slightly get another copy. Files that merely
change names also get another copy. This affects /var/log
especially, and it also affects MBOX style mail queues. The typical
way of
writing a log file involves appending messages
to file /var/log/foo for a week, then changing its name to
/var/log/foo.1 .
The file foo.1 becomes foo.2, and so forth.
This process is done by the program logrotate, and is typically
started by /etc/cron.daily/logrotate.
Thus every nightly version of "foo" is different, and every
week we make all new copies of foo.1, foo.2, etc. This uses a
lot of backup disk space.
One solution for this is the SUSE version of logrotate.
The SUSE distro has a special patch to Logrotate (not yet in
Redhat, Fedora, Mandrake, or other distros) to add the "dateext" option,
which adds a YYYYMMDD date string to the end of the "rotated" log
file names. After that, they are left alone until they are purged.
Redhat has assigned Elliot Lee to work on this,
bugzilla bug 108775, but there is no telling how long it will take
to fix. If you want to patch the 3.6.10 sources of logrotate yourself,
you can find the patches in Ruediger Oertel's directory at
SUSE.
This reduces the load that /var/log puts on the backups. It is
a hassle, and it deviates from the "redhat way of doing things",
but it does save space. Perhaps it is easier just to buy a bigger
backup drive, or expire more frequently.
Dirvish and mail
Personal mail files using the mbox protocol also accumulate
incrementally.
These can get pretty large, and can also change daily.
The solution to this is to convert the mailboxes from mbox protocol to
maildir protocol.
Rather than store all mail messages sequentially in a long file,
maildir stores each mail message as a separate file in a directory.
Maildir will use up lots of inodes on the main disk.
Maildir works with most modern mail readers (not elm) and with procmail.
I am told that Maildir works somewhat faster than mbox, especially
for large mail directories. Since my spam directory is *huge*, this
is an added benefit.
More about Maildir, and how to convert to it, as I learn about it.
Note also that if you are storing large databases for spam filters
like bogofilter, a database that grows daily will also fill up the
backups with incremental changes.
Fully using dirvish may change the way you use your system,
and you can get more out of dirvish if you set things up to avoid
incrementally accumulating files.
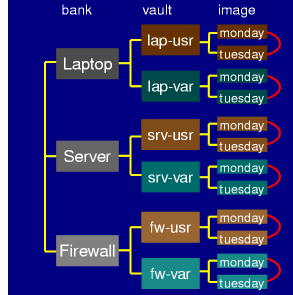
Dirvish - banks, vaults, branches, and images
One of the things that dirvish can do is store multiple "branches" of an
image for multiple machines that share very similar partitions or trees.
For example, if you have 10 desktops with identical /bin and /usr
partitions, you can use the branch metaphor to store these partitions
for all the different machines in one place.
I do not use this feature - all my machines are highly individualized,
and I typically bring up new distros on one machine first.
Thus, I have a separate "bank" for each machine, a "vault" for each
partition, and do not use branches, just daily images. Here is a
picture of how that looks -->
|
|
Setting up Dirvish
Here is the dirvish configuration file in
/etc/dirvish/master.conf
More later.
Some additional scripts for Dirvish
Dirvish does not save some things that would be *really handy* to
have when you restore your system.
Fortunately, you can call dirvish-runall from your own script in
/etc/cron.daily/backup,
and call your own scripts from inside Dirvish.
This is my backup script, which runs every day at 4am:
#!/bin/bash
# /etc/cron.daily/backup
# mount disks and run dirvish
# KHL October 7, 2003
PATH=/sbin:/usr/sbin:/bin:/usr/bin:/usr/local/sbin
BACKUPDRIVELOG=/var/log/backup_drivelog
# mount the backup drive
/bin/mount /dev/backup /backup
# log the backup drive
/bin/echo `/bin/cat /backup/DISKLABEL` `/bin/date` >> $BACKUPDRIVELOG
# do the backup itself
/usr/local/sbin/dirvish-runall
#unmount backups for safety
/bin/umount /dev/backup
I mount and unmount the backup drive for dirvish.
Everything on the backup drive is permission 700 and root only,
but leaving it unmounted means I can remove it at a whim and insure
that it is safe from system crackers.
Note also the "echo" line.
This adds a line to the file /var/log/backup_drivelog,
explaining which backup drive media was used for a
particular night's backup.
I also created another script,
dirvish-post,
which is run by dirvish after the rsync.
This routine saves copies of the output of df and
sfdisk on the backup drive.
This gives me critical information to rebuild the main drive from
bare metal. The comments in this script are self-explanatory.
#!/bin/bash
# /usr/local/sbin/dirvish-post
# KHL 10-6-2003
#
# This is run after dirvish completes. It assumes Linux clients at the
# far end of the pipe, and will need to be modified for other
# types of clients.
# client and destination, short form. for example,
# cl=laptop
# de=/backup/dirvish/laptop/laptoproot/2003-1006-0300
cl=$DIRVISH_CLIENT
de=$DIRVISH_DEST/..
# server commands
ssh='/usr/bin/ssh'
# client commands
sfdisk='/sbin/sfdisk -d /dev/hda '
df='/bin/df '
# Write df files to backup directory (image level) to keep
# track of disk usage, in case we need to rebuild a disk.
#
# This writes the $df info into each vault image, which is
# redundant but necessary given that dirvish is configured
# for multiple vaults per client.
$ssh $cl $df > $de/df.$i
# Write sfdisk files to backup directory (client bank level)
# in case we need to rebuild a disk.
# The file can be fed into sfdisk to rebuild what will become main drive.
# This will perform multiple overwrites of the same data.
$ssh $cl $sfdisk > $de/../../sfdisk.$i
### uncomment the below if you want to watch what dirvish is doing
# /bin/echo -n --------------------------------- >> /tmp/dirv
# /bin/echo ------------------------------------- >> /tmp/dirv
# /bin/date >> /tmp/dirv
# /bin/echo "SERVER = " $DIRVISH_SERVER >> /tmp/dirv
# /bin/echo "CLIENT = " $DIRVISH_CLIENT >> /tmp/dirv
# /bin/echo "SRC = " $DIRVISH_SRC >> /tmp/dirv
# /bin/echo "DEST = " $DIRVISH_DEST >> /tmp/dirv
# /bin/echo "IMAGE = " $DIRVISH_IMAGE >> /tmp/dirv
# /bin/echo "EXCLUDE = " $DIRVISH_EXCLUDE >> /tmp/dirv
# /bin/echo -n --------------------------------- >> /tmp/dirv
# /bin/echo ------------------------------------- >> /tmp/dirv
exit 0
More later.
Restore
With the saved data, it is pretty easy to restore a hard drive from
bare metal. Right now, I use an ad-hoc, hand written
bash script which does these steps:
use the "sfdisk" output to repartition the new drive (assuming same size)
mkfs the partitions on the new drive
mkswap swap partitions
mount and copy data partitions
chmod /tmp partition (which dirvish doesn't save) for world rwx
mkdir /proc (which dirvish doesn't save)
install grub with "grub --batch"; I can't get grubinstall to work
On a 120GB new drive with 60GB of restored data, this process takes
about 3 hours with the new drive in the USB2 swap cage. If set up
properly, it needs no minding, so go see a movie!
More later.
MORE LATER - This is a work in progress. I hope this has been useful
so far, check back again in a few weeks, or send me more ideas and text.
Presentations about dirvish and rsync
Linuxfest Northwest, April 17, 2004 Slides,
OpenOffice Impress (v1.1.0) format,
PDF format.
Portland Linux Unix Group, March 4, 2004 Slides,
OpenOffice Impress (v1.1.0) format,
PDF format.
Notes
ViPower versus InClose cages: I originally implemented this
with
SanMax InClose drive swap cages. The InClose USB cages work a little
faster, and are available at the nearby Fry's; however, I have discovered
that the InClose cage will lock up the USB controller (both NEC
and VIA chipset boards) under the high data rates involved in restoring a
drive. Rsync backups work just fine with either product. The ViPower
cage is 50% slower, but it does a clean restore without problems.
I do not know why the InClose has the problem, but I suspect
that the problem lies in the kernel. The InClose cage USB2 controller
is is a programmable Cypress C7Y68013 controller. The FIFO buffers on
the Cypress chip are twice the size of the ViPower's GL811 interface,
which accounts for their speed. I sent SanMax a bug report in early
November, and they did some testing for me under Windoze - no problem
found. The error occurs about once per hour at full speed transfer,
so this is going to be very difficult to find.
Note - this bug is still in the 2.6.3 kernel, which does not
do IDE hotswap.
Spare drive trays: These can change mechanically. Once you
convince yourself that this all works, buy an extra cage or two, and
lots of spare drive trays. That way, you won't have to change
everything over if you need to replace something after they make yet
another mechanical change.
The cage key: The ViPower LSF series uses a slide switch,
while the KSF series uses a key to release the drive tray and turn
off the power. You get two keys with each cage; they are all
ultra-simple cylinder locks and all the same key. Build a little hook
to hold one of the keys; I have a door on my drive bay and taped a
hook inside that. Store the other keys where you won't lose them.
Promise drive controllers: The big retail-boxed Maxtor drives
usually come with a rebranded
Promise
Ultra133 TX2 drive controller (PDC20269 chipset).
The older boxes came with a dual ATA-133 controller,
which means the main and the backup drives can be on
separate cables ( this is faster and easier to route in the box).
The newer retail boxes come with a Promise SATA150 TX2plus card,
with a single ATA-133 port and two SATA ports.
I guess they got lazy and decided to put the same card
in both PATA and SATA retail boxes.
Too bad; it means you will be buying another separate ATA133 controller.
The Ultra133 TX2 card works fine with Linux (at least, RH9 and Fedora FC1);
I wasn't able to get the PATA port of the SATA150 card to work,
though I did not try very hard. Bartlomiej tells me that PATA port
support for this card is under development.
devlabel: The Redhat configuration wants to build drives with
labeled partitions, and put those labels in the grub.conf grub
configuration line. Sometimes the machine will start booting from
the drive in /dev/hdc or /dev/hde, then use the configuration
information to start looking for a drive that isn't there, or else
find two drives with a /boot label. This can be a problem when you
are swapping drives around for backups and rebuilding. I'm not
sure of what the elegant way to handle this is, but be aware that an
incomplete partition labelling strategy can result in strange behavior.
slocate: Every night, a Redhat cron script runs updatedb to
build the /var/lib/slocate/slocate.db database for slocate. You don't want
slocate to try to build this table based on the backup disk; it will create
an enormous table! So you want to modify /etc/cron.daily/slocate.cron and
add /backup (or whatever) to the list of excluded directories after the
-e switch on the command line of the script.
Alternatives to dirvish: There is more than one way to do
disk-to-disk backups. Consider
backuppc
if you have a large number of very similar machines. Backuppc
keeps track of identical files, regardless of their position in the
directory tree, and stores them as a pool of files with hashed
pointers to them. Thus, if a file is stored as /home/fred/schedule
on machine A, and as /home/sam/fredschedule on machines A and B,
it will get stored only once on the backup, with three pointers.
The best thing about backuppc is how it restores single files, with
a simple web interface for users to ask for their backups, securely
and without operator intervention. I am not sure how backuppc
compares speed-wise to dirvish.
Mike Rubel's
rsync snapshots has evolved into Nathan Rosenquist's
rsnapshot,
which is another way to drive rsync. rsnapshot is also server
driven (I was wrong about this earlier). It is simpler to use
but less versatile than dirvish.
rdiff-backup
stores files and then incremental changes to them. This seems like a
good way to deal with the "expanding log or mail file" problem, but
does not deal with some of the issues that dirvish and backuppc deal with.
Probably the best rsync solution will combine aspects of all these systems,
along with other features like distributed and network-load-aware backup
servers.
Fortunately, the structure of Unix/Linux and the cross-fertilization of
the open-source/free-software community will make these combinations
occur robustly and rapidly.
To all you system crackers out there:
Yes, I'm sure this data will help you crack open my machines like the
cheap tincans they are.
Before you do so, please consider what kind of world you want to have.
This webpage is here to help other people; you included!
If you use this to take me out, I have to stop to clean up the mess
rather than have time to write more web pages that could help you.
There are probably a lot of things you would rather be doing than
figuring out, all on your own, the things you could learn here.
So please think twice before you attack using this information.
Perhaps, instead of an attack, you could send me email pointing out
how to do this backup job better.
I can add that to this page, and credit your contribution publically
(I don't need to know that you also crack systems).
That will make you feel good, and increase your reputation in the
Linux community. Linux is strong and vital because a lot of smart
people like you also like to feel good about sharing and helping.
It is a wonderful thing. Join us!
Acknowlegements:
J.W. Schultz wrote dirvish, thanks! Thanks also to the folks that
wrote rsync, ssh, and all the other tools that went into this.
Thanks to Linus Torvalds for Linux, of course, and thanks to
Andre Hedrick for the LBA48 drivers, and Alan Cox for his work on IDE
hotswap and some helpful email. Thanks to Elliott Mitchell for helping
me figure out the "z" option on hdparm. Valuable feedback from
Bartlomiej Zolnierki. And thanks to all the millions of Linux
developers, documenters, and users that make this a great community
to share with!
www.keithl.com/linuxbackup.html by Keith Lofstrom,
keithl AT keithl DOT com
last revision 2004 September 12